GC란?
가비지 컬랙션이란 힙에서 참조되지 않는 객체들을 탐색 후 삭제하는 과정으로 삭제된 객체의 메모리를 반환하여 힙 메모리를 재사용할 수 있게 하는 것이다. 힙 영역의 객체 중 stack의 변수와 연결이 끊겨 도달 불가능한 인스턴스들은 가비지 컬랙션의 대상이 된다.
MinorGc
- Young영역(Eden + Survivor1 + Survivor2)에서 이용하지 않는 메모리가 지워지는 과정을 MinorGc라 한다.
- 새로 생성한 대부분의 객체는 Eden영역에 위치한다.
- Eden 영역에서 Gc가 한번 발생한 후 살아남은 객체는 Survivor영역 중 하나로 이동된다.
- Eden 영역에서 계속 Gc가 발생함에 따라 Survivor영역에도 객체가 계속 쌓인다.
- 하나의 Survivor영역이 가득 차면 그중에서 살아남은 객체를 다른 Survivor영역으로 이동시킨다. 그리고 가득 찬 Survivor영역은 비운다.
- 이 과정을 반복하다가 계속해서 살아남아 있는 객체는 Old영역으로 이동하게 된다.
- Survivor영역 중 하나는 반드시 비어있는 상태가 되어야 하며. 만약 두 Survivor영역에 모두 데이터가 존재하거나 두 영역 모두 사용량이 0이라면 시스템은 정상적인 상황이 아니라고 생각하면 된다.
FullGc
- Young영역에서 오랫동안 살아남은 인스턴스가 저장되는 곳이 Old영역인데 이 영역이 초기화될 때 일어나는 Gc를 FullGc라고 한다.
- FullGc가 일어나면 인스턴스를 하나하나 확인해가며 참조 관계를 따지고 참조 관계가 없는 인스턴스를 체크한 다음 한꺼번에 제거하는데 이때 수초 이상 걸리기 때문에 STW(Stop the world – Gc가 수행되는 동안 애플리케이션이 멈추는 현상)가 발생할 수 있다.
HAProxy에서 HA란 무엇인가?
HA(High Availability – 고가용성)
서비스의 다운타임을 최소화 함으로써 가용성을 극대화하는 것을 말한다. 운영서버에 장애가 발생하더라도 대기 서버가 즉시 서비스를 대신 처리해 준다면 다운타임이 최소화될 수 있다. HA는 관리자가 없을지라도 운영 서버의 장애를 모니터링해 대기 서버가 처리할 수 있도록 함으로써 중단 없이 서비스를 제공하는 것을 말한다.
DB 인덱스란?
- 테이블에 저장된 데이터를 빠르게 조회하기 위한 데이터 베이스 객체
- DB에서 테이블을 만들고 데이터를 추가 수정 삭제할 때 데이터 레코드는 내부적으로 아무런 순서 없이 저장된다. 인덱스가 없는 테이블의 데이터를 찾을 때 처음 레코드부터 마지막 레코드까지 모두 읽어 검색하는데 이것을 풀 스캔이라고 한다.
- 데이터 양이 많은 테이블에서 풀 스캔을 하면 성능이 떨어지므로 where, join, order by등과 관련된 칼럼 중 사용빈도가 높고 키값의 선별도가 좋은 칼럼을 인덱스로 설정한다.
- 인덱스는 내부적으로 B+-Tree를 사용하는데 칼럼의 값을 변형하지 않고 원래 값을 이용해 인덱싱 하는 알고리즘이다.
- 칼럼의 값으로 해시값을 구하여 인덱싱 하지 않는 이유는 해시의 경우 값을 변형해서 인덱싱 하므로 특정 문자로 시작하거나 값의 일부만으로 검색하거나, 부등호 등의 연산을 할 수 없기 때문이다.
Call By Value / Call By Reference 차이
함수를 호출할 때 전달 파라미터를 값으로 하여 호출하느냐, 참조로 해서 호출하느냐에 따라 차이가 발생한다.
Class CallByValue {
public static void swap(int x, int y) {
int temp = x;
x = y;
y = temp;
}
public static void main(String[] args) {
int a=10;
int b=20;
System.out.println("swap() 호출 전 : a = "+a+", b = "+b);
swap(a,b);
System.out.println("swap() 호출 후 : a = "+a+", b = "+b);
}
}
// swap() 호출 전 : a = 10, b = 20
// swap() 호출 후 : a = 10, b = 20
public class CallByReference {
int value;
CallByReference(int value) {
this.value = value;
}
public static void swap(CallByReference x, CallByReference y) {
int temp = x.value;
x.value = y.value;
y.value = temp;
}
public static void main(String args[]) {
CallByReference x = new CallByReference(10);
CallByReference y = new CallByReference(20);
System.out.println("swap() 호출 전 : x = "+x+", y= "+y);
swap(x, y);
System.out.println("swap() 호출 후 : x = "+x+", y= "+y);
}
}
// swap() 호출 전 : x = 10, y = 20
// swap() 호출 후: x = 20, y = 10
함수형 프로그래밍이란?
순수 함수를 이용하여 공유 상태(shared state), 변경 가능한 데이터(mutable data), 부작용(side effect)을 최소화하여 프로그램을 만드는 프로세스를 말한다.
변경 가능한 상태를 불변(immutable) 상태로 만들어 부작용을 없앤다.
순수 함수를 사용하여 같은 입력은 항상 같은 결괏값이 나오게 한다. 함수 안에서 상태를 사용하여 사이드 이펙트가 발생하지 않도록 한다.
모든것은 객체이다.
함수형 언어에서는 모든 것이 객체이다. 클래스 외에 함수 또한 객체이기 때문에 함수를 값으로 할당할 수 있고, 파라미터로 전달 및 결과 값으로 반환이 가능하다.
간결한 코드로 가독성을 높이고 로직에 집중
Lambda 및 Collection, Stream과 같은 api를 통해 보일러 플레이트를 제거하고, 내부에 직접적인 함수 호출을 통해 가독성을 높일 수 있다.
동시성 작업을 보다 쉽고 안전하게 구현
불변 상태 값을 이용해, 여러 스레드에서 접근을 하더라도 부작용이 발생하지 않는다.
박싱, 언박싱 차이
해당 타입에 맞게 기본형 타입을 객체에 넣는 것을 Boxing, 반대를 Unboxing이라고 한다.
Boxing – Primitive Type => Wrapper Class
ex) Integer a = new Integer(10);
Unboxing – Wrapper Class => Primitive Type
ex) int b = a.intValue();
오토 박싱의 경우 명시적으로 Primitive타입을 Wrapper클래스로 감싸주지 않아도 Boxing 해주는것.
ex) Integer a = 3 // 내부적으로 new Integer(3)으로 동작한다.
오토 언박싱의 경우 그 반대로, 명시적으로 Primitive 타입으로 변환하지 않아도 Unboxing 해주는것을 의미
ex) Integer a = new Integer(3);
int b = a; // 내부적으로 a.intValue()로 동작한다.
mutable, immutable 차이
불변 객체(immutable)객체란 생성 후에 바꿀수 없는 객체를 말한다. 가변 객체(mutable)는 생성 후에도 상태를 바꿀 수 있는 객체이다. 보통의 불변 객체는 객체를 복사하게 되면 객체 자체가 아닌 참조값을 복사만 하고 끝난다. 즉 메모리에 똑같은 게 하나 더 생성되는 것이 아니라 그 객체를 가리키는 포인터가 하나 더 생성된다고 보면 된다. 데이터가 불변 객체에 저장되어있다면 여러 스레드에 의해서 객체 안의 데이터에 접근을 하게 되었을때 데이터 변경 우려가 없고 해당 객체를 Thread Safe 하다고 한다.
마이크로 서비스란?
아주 작은 독립적인 기능을 수행하는 여러 개의 마이크로 서비스를 묶어서 하나의 비즈니스 기능을 구현하는 방식을 마이크로 서비스 아키텍쳐라고 한다.
장점
- 시스템을 작은 단위로 구성함으로써 각 서비스별로 독립적인 개발 및 배포를 진행할 수 있다.
- 서비스별로 병렬 개발이 가능하고, 서비스 특징에 맞는 개발언어 및 DB를 자유롭게 적용할 수 있다.
- 운영 중에도 각 서비스별로 배포, 확장, 축소 등을 자유롭게 할 수 있다.
단점
- 단위 서비스의 복잡도는 줄어들지만 전체 시스템의 복잡도는 더 증가할 수 있다.
- 운영 중 장애 발생 시 장애 지점을 찾기 어려우며 각 서비스를 하나의 트랜잭션으로 묶기 어렵다.
- 연결된 서비스들이 많기 때문에 자동화된 테스트 코드 작성 시 고려해야 될 사항이 많다.
스택오버플로우란?
stack영역의 메모리가 지정된 범위를 넘어갈 때 발생한다. Stack에는 보통 지역변수가 저장된다. 함수에서 지역변수를 선언하면 지역변수는 Stack메모리에 할당되고 함수를 빠져나오면 Stack메모리에서 해제된다. 하나의 프로그램이 실행될 때 수많은 함수를 호출하고 빠져나오는데 그때마다 함수에서 사용하는 지역변수는 stack에 할당되고 해제되는 것을 반복하게 되며 그에 따라 사용되는 stack영역이 변하게 된다. 한 함수에서 너무 큰 지역변수를 선언하거나 재귀 함수를 무한정 호출하게 되면 스택오버플로우가 발생할 수 있다.
브라우저에서 주소를 입력했을때의 과정
- 사용자가 브라우저에 URL을 입력
- 도메인을 해석하기 위해 DNS 서버로 접근하여 도메인 네임에 맞는 IP를 받는다.(브라우저에 캐시 된다.)
- ARP(Adress Resolution Protocol)로 대상의 IP와 물리적 주소인 Mac Address를 알아낸다.
- 대상을 찾으면 TCP 통신을 통해 Socket을 연다.
- HTTP 프로토콜로 서버의 리소스를 요청하고 서버의 응답 결과를 웹브라우저에 표시한다.
번들러란?
bundler란 필요한 의존성을 추적하여 해당하는 의존성들을 그룹핑해 주는 도구이다. 자바스크립트 번들러란 사용자의 코드와 종속성이 있는 자바스크립트 파일을 통합해주는 도구이다.
영속성 컨텍스트
엔티티(테이블과 매핑되는 객체)를 저장하는 논리적인 저장공간을 말한다.
동작
- 조회할 데이터가 영속성 컨텍스트에 존재하는지 확인
- 존재하지 않으면 쿼리를 생성
- 쿼리를 DB에 전송
- 결과 값을 영속성 컨텍스트가 전달받는다.
- 전달 받은 데이터를 엔티티로 저장한다.
- 엔티티 인스턴스를 리턴한다.
장점
- select * from user where id=1로 데이터를 조회하면 동일 아이디로 쿼리 재요청 시 영속성 컨텍스트의 엔티티를 가져와 재사용한다.
- 비즈니스 로직에서 insert, update, delete 등을 여러 번 구현했을 때 코드가 수행될 때마다 DB에 요청을 보내는 것이 아니라 영속성 컨텍스트는 쿼리를 생성하여 저장해 두었다가 flush 되는 순간에 한꺼번에 DB로 요청을 보낸다(쓰기 지연)
- 업데이트 처리가 필요할 때 User user = em.find(User.class, 1)과 같이 엔티티를 가져온 후 user.setName(‘happydaddy’);와 같이 엔티티의 속성 값을 변경하면 엔티티 매니저가 flush될 때 update문을 DB로 요청한다. Dirty Checking이라고 하며 엔티티 상태 변경을 검사하여 적용하는 것을 의미한다.
- 지연 로딩을 통해 특정 엔티티의 데이터를 사용하는 시점에 DB에 요청을 보낼 수 있다.(Lazy loading)
- 기본적인 CRUD 쿼리를 안 만들어도 된다.
- 관리할 쿼리가 많이 줄어들고 코드화 되므로 리팩터링이 쉬워진다.
n+1 쿼리
JPA에서 조회를 위해 select쿼리를(1번) 수행하는데 연관된 엔티티 정보를 얻기 위해 또 다른 N번의 select를 하게 되는 상황을 n+1 쿼리 문제라 한다.
- 책과 저자 정보가 @ManyToOne의 관계를 가지고 있을 때 책을 조회하면 저자 정보가 Eager전략에 의해 같이 조회된다. 즉 책을 조회하면 저자 정보를 조회하는 쿼리가 1회 발생한다.
- 즉, 책 목록을 조회하면 책 목록 쿼리 1번 + 책 목록만큼의 저자 정보 쿼리 N번이 발생한다.
- 일반적인 쿼리를 사용하였다면 JOIN을 통해 1번의 쿼리로 해결되는 문제지만, JPA구조상 엔티티 간 관계를 맺을 때 fetch전략에 의해 이러한 문제가 발생한다.
- 저자 정보를 지연 로딩을 사용할 수 있지만, 책 정보와 저자 정보가 동시에 필요한 경우가 있을 수 있다. fetch join을 이용(left join 뒤에 fetch를 추가)하거나 @EntityGraph를 이용하면 JPA에서 join을 사용하여 쿼리를 한 번만 수행한다.
inner join, outer join 설명 및 차이점
inner join은 교집합. outer join(left, right, full)은 기준 테이블 쪽의 모든 결과를 보여주고 반대쪽에 매칭 되는 값이 없어도 보여주는 JOIN이다.
union 쿼리
각각의 select문의 결과를 합쳐주는 쿼리 union만 사용하면 중복된 값을 제외하고 보여준다. union all을 하면 합치기만 하므로 중복된 결과가 있을 수 있다.
JWT란?
- JSON Web Token은 JSON객체로서 당사자간에 안전하게 정보를 전송할 수 있는 방법을 정의하는 공개 표준이다.
- JWT는 서명(공개키/개인키)을 할 수 있기 때문에 신뢰하는 발신자인지 확인할 수 있다.
- 서명이 헤더와 페이로드를 이용하여 계산되므로 내용이 변조되지 않았는지 확인할 수 있다.
- 토큰 헤더는 JWT토큰 유형과 사용되는 해시 알고리즘(SHA256, RSA등..)으로 구성된다.
- 토큰의 중간 부분은 클레임이 들어있는 페이로드로 구성된다. 클레임은 엔티티(일반적으로 사용자)와 추가 데이터에 대한 설명으로 구성된다.
- 토큰의 마지막 서명 부분은 메시지가 변조되지 않았음을 확인하는 데 사용하며, 서명된 토큰의 경우 JWT발신자가 올바른 대상인지 확인할 수 있다.
프로세스와 쓰레드
Process
- 실행 중인 프로그램. 리소스와 스레드로 구성되며 모든 프로세스는 한개이상의 스레드를 가진다.
- 프로세스는 code, data, stack, heap 영역을 가지고 있다.
Thread
- 경량화된 프로세스로 프로세스 내에서 실제 작업을 수행한다.
- 프로세스는 하나의 독립적인 메모리 공간을 할당받아 사용하지만 스레드는 Stack을 제외한 영역을 공유하기 때문에 메모리 자원 사용을 줄일 수 있다.
프로세스는 스레드에 비해 많은 자원을 가지고 있어야 하기 때문에 ContextSwitching 비용이 많이 든다. 스레드의 경우에는 Stack을 제외한 모든 자원을 공유하므로 프로세스에 비해 Context Switching 비용이 낮다. 스레드의 경우 스레드 간 자원 공유가 가능하여 편리하지만 자원 동기화의 문제가 있을 수 있다.
Reactive Programming
Reactive Programming은 기본적으로 모든 것을 스트림으로 본다, 이벤트, ajax call 등 모든 데이터의 흐름을 시간 순서에 의해 전달되는 스트림으로 처리한다. 즉 스트림이란 시간순서에 의해 전달된 값들의 Collection이다. 각각의 스트림은 새로 만들어 지거나(branch) 여러 개의 스트림이 합쳐(merge)질 수도 있다. 또한 스트림은 map, filter와 같은 함수형 메서드를 이용하여, immutable하게 처리할 수 있다. 또한 스트림을 subscribe 하여 데이터의 결과값을 비동기로 처리할 수도 있다.(성능 향상)
HashMap, HashTable차이
HashMap의 경우 동기화를 지원하지 않아 빠른 성능을 제공한다. HashTable은 다중 스레드 환경에서 동기화를 지원하기 때문에 환경에 따라 구분하여 사용할 수 있다. 그런데 Java5부터 더 높은 성능에 동기화를 지원하는 ConcurrentHashMap을 제공하기 때문에 HashTable 대신 사용하는 것이 좋다.
MVC 패턴 중 비지니스 로직은 어디에 있어야 하는가?
비즈니스 로직이 Model이라는 의견이 지배적인 것으로 봐서 Model에 비즈니스 로직이 담겨있는 것은 자명하다고 보고, model과 view를 중개하는 역할만을 controller가 하도록 구현하는 편이 바람직한 것 같다는 생각이 든다. 그렇게 해야 역할과 책임의 분리가 명확하게 되는 것 같기도 하다.
추상 클래스와 인터페이스의 차이
추상 클래스와 인터페이스는 상속받는 클래스 혹은 구현하는 인터페이스 안에 있는 추상 메서드를 구현하도록 강제한다. 다만 사용목적이 다른데 추상 클래스는 상속받아서 기능을 이용하고, 확장하여 사용하는데 목적이 있다. 반면 인터페이스는 메서드의 껍데기만 있으며 메서드의 구현을 강제한다. 또한 추상클래스는 하나만 상속 가능하지만, 인터페이스는 다중 상속이 가능하고, 인터페이스를 구현한 객체들 간에 대해서 동일한 동작을 약속하기 위해 존재한다.(DBCP나 DataSource 같은… 다형성이 필요한 것들의 구현)
코드영역, 데이터, 스택, 힙 영역
코드(code)영역
- 메모리의 코드 영역은 실행할 프로그램의 코드가 저장되는 영역으로 텍스트 영역이라고도 한다. CPU는 코드 영역에 저장된 명령어를 하나씩 가져와 처리하게 된다.
데이터(data)영역 – static area
- 메모리의 데이터 영역은 프로그램의 전역 변수와 정적 변수가 저장되는 영역이다.
- 데이터 영역은 프로그램의 시작과 함께 할당되며 프로그램이 종료되면 소멸한다.
- JAVA 파일의 필드 부분에 선언된 전역 변수와 정적 멤버 변수는 static영역에 데이터를 저장한다.
스택(Stack) 영역
- 메서드 내에서 정의하는 기본자료형(int, double, byte, long, boolean 등)에 해당하는 지역변수(매개변수 및 블록 문내 변수 포함)의 데이터의 값이 저장되는 공간. 즉 함수의 호출과 관계되는 지역변수와 매개변수가 저장되는 영역이다.
- 스택 영역은 함수의 호출과 함께 할당되며 함수의 호출이 완료되면 소멸한다.
힙(Heap) 영역
- 참조형(Reference Type)의 데이터 타입을 갖는 객체, 배열등이 저장되는 공간이다.
- 힙 영역은 사용자에 의해 메모리 공간이 동적으로 할당되고 해제된다.
- 변수는 stack영역의 객체에서 실제 데이터를 갖고 있는 힙 영역의 참조값을 얻을 수 있고 이 참조값을 가지고 있는 객체를 통해 인스턴스를 핸들링할 수 있다.
데드락 발생요인과 해결책
프로세스가 자원을 얻지 못해 다음 처리를 하지 못하는 상태로, 교착상태라고도 하며 시스템적으로 한정된 자원을 여러 곳에서 사용하려고 할때 발생한다.( 멀티스레드로 같은 DB 테이블에 select, update 동작을 하게 하면 심심치 않게 볼 수 있다. )
상호 배제 조건의 제거
여러 개의 프로세스가 공유 자원을 사용할 수 있도록 한다.
점유와 대기 조건의 제거
프로세스가 실행되기 전 필요한 모든 자원을 할당한다. 자원 과다 사용으로 인한 효율성, 프로세스가 요구하는 자원을 파악하는 데에 대한 비용, 자원에 대한 내용을 저장 및 복원하기 위한 비용, 기아상태, 무한 대기 등의 문제점이 있다.
비선점 조건의 제거
자원을 점유하고 있는 프로세스가 다른 자원을 요구할 때 점유하고 있는 자원을 반납하고, 요구한 자원을 사용하기 위해 기다리게 한다.
순환 대기 조건의 제거
자원에 고유한 번호를 할당하고, 번호 순서대로 자원을 요구하도록 한다. 자원 사용의 효율성이 떨어지고 비용이 많이 드는 문제점이 있다.
Context Switching(문맥교환)이란?
- 현재 진행하고 있는 Task(Process, Thread)의 상태를 저장하고 다음 진행할 Task의 상태 값을 읽어 실행하는 과정을 말한다.
- CPU가 현재 처리 중인 프로세스의 PCB(Process Control Block)을 따로 저장하고 다른 PCB를 가져오는 것을 말한다.
- 한 번에 하나의 프로세스만 처리할 수 있는 CPU에게 동시에 여러 가지 일을 시킬 때 CPU는 IO인터럽트나 시스템 콜에 의해 이프로세스 저프로세스를 아주 빠르게 왔다 갔다 하며 처리한다. 이때 일어나는 것이 문맥 교환이다.
- 문맥 교환 비용은 Process가 Thread에 비해 많이 든다. Thread는 Stack영역을 제외한 나머지 자원을 공유하기 때문에 문맥 교환 발생시 Stack영역만 변경 진행하면 되기 때문이다.
JVM 이란
- Java Virtual Machine의 줄임말이며 Java Byte Code를 OS에 맞게 해석해주는 역할을 한다.
- Java Compiler는 java파일을 class라는 bytecode로 변환시켜준다.
- Bytecode는 기계어가 아니기 때문에 OS에서 바로 실행될 수 없고 JVM이 Bytecode를 OS가 이해할 수 있도록 해석하여 처리한다.
JVM 구성
JVM은 ClassLoader, Execution Engine, Runtime Data Area(메모리 영역)로 구성된다.
- ClassLoader – 런타임 시점에 컴파일된 java bytecode의 인스턴스를 Runtime Data Area에 로드한다.
- Execution Engine – ClassLoader를 통해 Runtime Data Area에 로드된 bytecode를 실행한다.
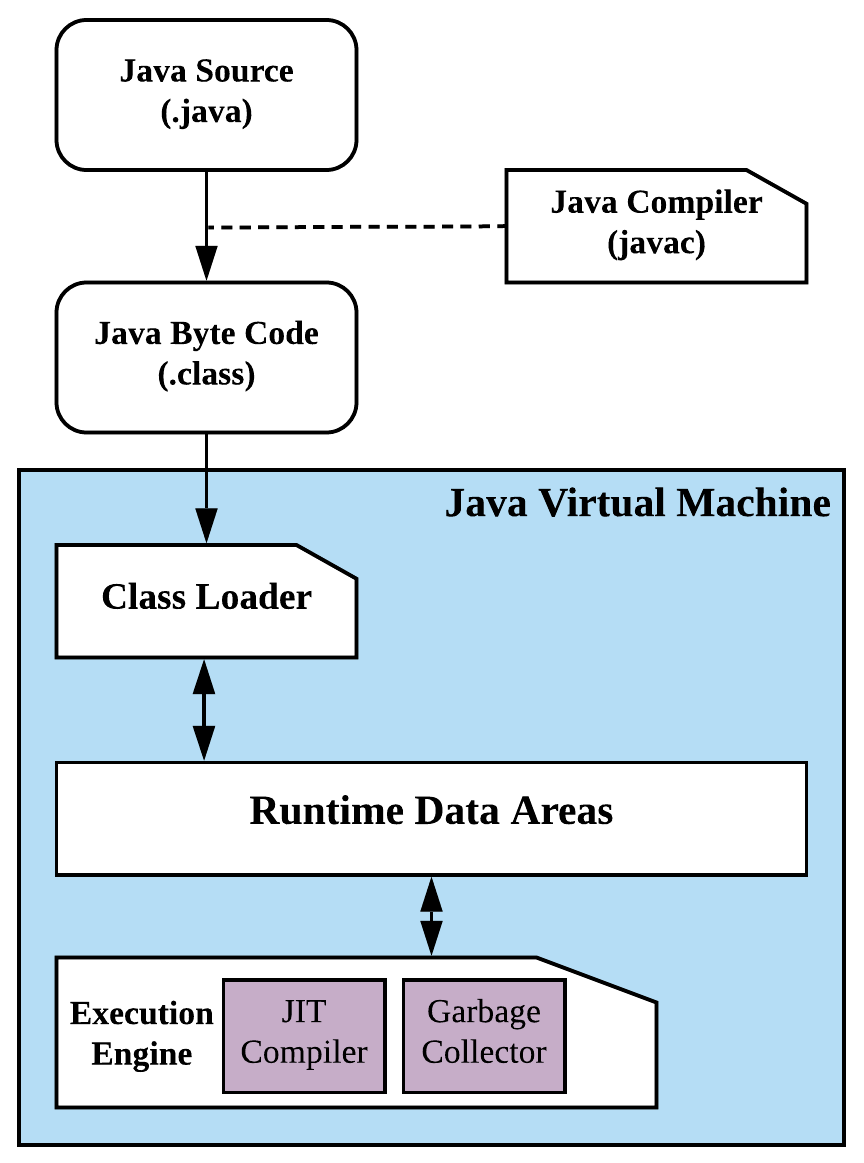
Runtime Data Area(메모리 영역)
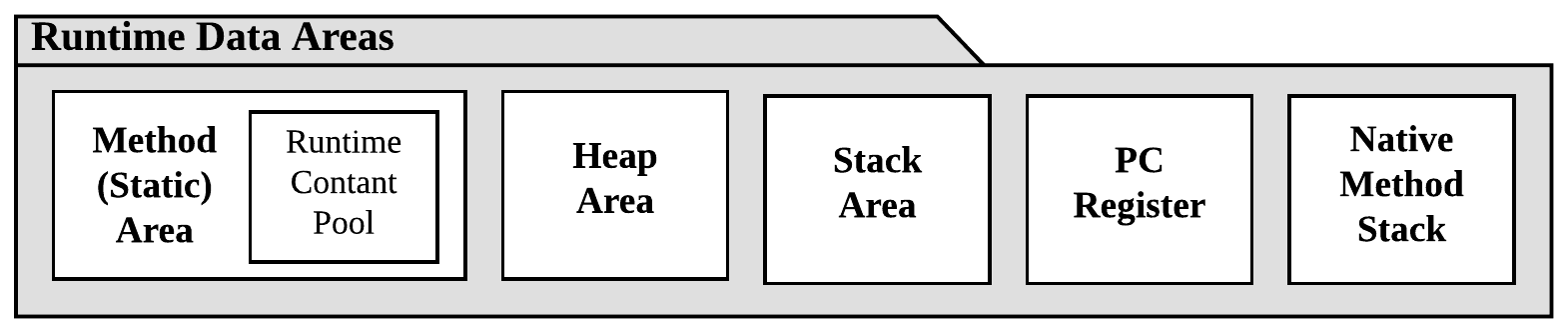
Runtime Data Area(메모리 영역)은 총 5개의 영역으로 나뉘어진다.
Method(static) 영역
Class와 관련된 프로그램 상의 모든 패키지, 클래스, 인터페이스, 필드와 메서드, static변수들이 저장된다.
Heap 영역
new를 통해 생성된 객체와 배열의 인스턴스가 저장된다. 힙 영역에 생성된 객체와 배열은 Stack영역의 변수나 다른 객체의 필드에서 참조하며 이 영역은 GC의 대상이 된다.
Stack 영역
메서드(함수)가 실행되면 스택 영역에 메서드에 대한 영역이 하나 생긴다. 이 영역에는 해당 메서드에서 사용하는 지역변수, 매개변수, 리턴 값등이 저장된다. 만약 값이 아닌 참조일 경우에는 힙 영역에 있는 인스턴스의 주소 값을 가리킨다.
PC Register
스레드가 시작될 때마다 생성되는 공간으로 스레드마다 하나씩 존재한다. Program Counter 즉 스레드가 실행되는 부분의 주소와 명령을 저장하고 있는 영역으로 스레드를 돌아가며 수행할 수 있게 한다. 현재 수행 중인 JVM명령의 주소를 갖는다.
Native Method Stack
Java 외의 다른 언어로 작성된 네이티브 코드들을 위한 Stack으로 JNI(Java Native Interface)를 통해 호출되는 코드를 수행하기 위한 Stack 공간이다.
Heap 영역 상세
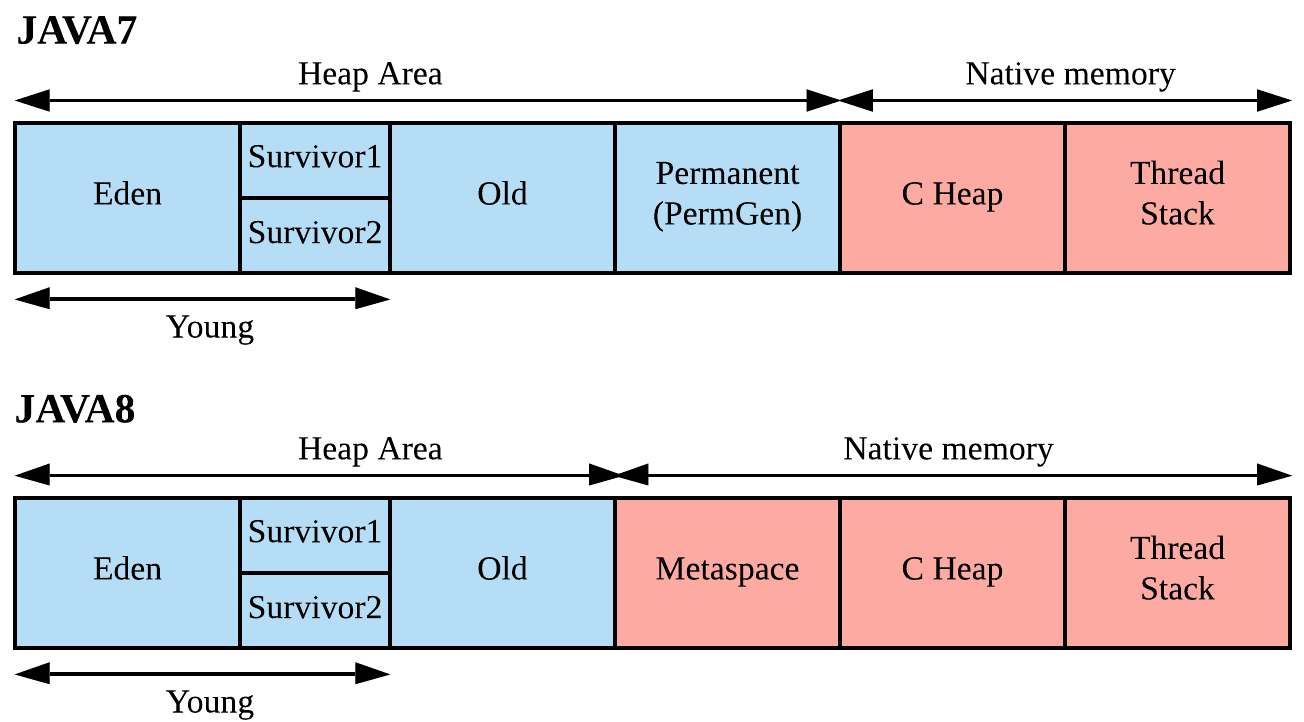
eden, suvivor 0,1, old, permanent영역으로 구분된다. 이중 permanent영역은 거의 변하지 않는 정보. 즉, 클래스나 메서드의 meta정보나 상수 풀등이 저장되는 공간이었는데 Java8에서부터 영역이 삭제되었다. 해당 영역의 데이터는 새로 생성된 Metaspace 영역과 기존의 Heap 영역에 나뉘어 저장되게 되었다. Metaspace는 Native(OS)가 관리하는 영역으로 기존의 Perm영역 확보를 위해 개발자가 신경 쓸 필요가 없어졌다.
equals 오버라이드시 주의점은 무엇인가?
- equals 메서드를 override 할 때는 hashCode 메서드도 항상 같이 오버라이드 한다. 그렇지 않으면 Hash기반의 컬렉션들과 클래스를 같이 사용할 때 올바르게 동작하지 않을 가능성이 높다.
- 애플리케이션 실행 중에 같은 객체에 대해 한번 이상 호출되더라도 hashcode메서드는 같은 정수를 일관성 있게 반환해야 한다. equals(object) 메소드 호출 결과 두 객체가 동일하다면 두 객체 각각에 대해 hashCode 메서드를 호출했을때 같은 정수 값이 나와야 한다.
public class User {
public String name;
public int age;
public String job;
public User(String name, int age, String job) {
this.name = name;
this.age = age;
this.job = job;
}
@Override
public boolean equals(Object obj) {
if(obj instanceof User) {
User user = (User)obj
return this.name.equals(user.name) && this.age = user.age;
} else {
return false;
}
}
@Override
public int hashCode() {
int result = 1;
result = 31 * result + age; // 31은 소수이고 bit 연산이 쉬워 성능이 향상된다.
result = 31 * result + (name==null ? 0 : name.hashCode());
return result;
}
}
Http와 Https의 차이점
- http는 웹브라우저가 웹서버에 html 문서를 요청하는 프로토콜이다. 80 포트를 사용한다.
- http는 단순한 텍스트 교환이기 때문에 네트워크상에서 데이터를 가로챈다면 내용이 그대로 노출된다.
- https는 http에서 모든 통신내용을 암호화하는것이다. 443 port로 통신이 이루어진다.
- 암호화는 공개키 암호화 방식이 사용되는데 테이터를 주고받을 때 공개키로 암호화시킨 데이터는 서버가 가진 개인키로만 복호화가 가능하다.
- 응답을 받은 서버는 개인키로 암호화한 데이터를 클라이언트에게 보내는데 클라이언트는 공개키로 해당 데이터를 복호화할 수 있다.
- 공개키는 누구나 얻을 수 있고 서버로부터 받은 데이터를 누구나 복호화할 수 있는데 이것으로 해당 서버에서 온 응답임을 확신할 수 있다.
- 공개키 저장소는 CA(Certificate Authority)라고 하며 세계적으로 신뢰성이 검증된 기업만이 운영할 수 있다. 일반 기업은 이 CA에 돈을 내고 회사 정보와 공개키의 암호화 방법 등이 담긴 인증서를 등록하고 클라이언트에게 제공하게 된다.
http와 tcp의 차이
- 가장 큰 차이점은 tcp/ip는 transport 계층에서 동작한다. http는 application계층에서 동작한다. 이 계층에서 동작하는 프로토콜은 http 말고도 smtp, ftp등이 있다.
- 개념적으로 보면 http, ftp 등의 프로토콜은 tcp/ip 위에서 동작하는 것이라고 볼 수있다.
TCP/IP 4계층
| 레벨 | 계층 | 기능 |
| 4계층 Application | 응용 계층 프로토콜 : HTTP, FTP, Telnet, DNS, SMTP | OSI 7계층의 5,6,7 계층에 해당한다. TCP/IP기반의 응용프로그램을 구분할때 사용한다. |
| 3계층 Transport | 전송 계층 프로토콜: TCP/IP, UDP | OSI 7계층의 4계층에 해당한다. 통신 노드간의 연결을 제어하고 자료의 송수신을 담당한다. |
| 2계층 Internet | 인터넷 계층 프로토콜 : IP,ARP,RARP,ICMP,OSPF | OSI 7계층의 3계층에 해당한다. 통신노드간의 IP패킷을 전송하는 기능 및 라우팅 기능을 담당한다. |
| 1계층 Network Interface | 네트워크 인터페이스 계층 프로토콜 : Ethernet, Token Ring, PPP | OSI 7계층의 1,2계층에 해당한다. CSMA/CD, MAC, LAN, X.25, 패킷망, 위성통신 다이얼 모뎀등 전송에 사용된다. |
TCP
- byte array(binary)로 정보를 통신한다.
- 언제나 서버와 연결되어있어야 하며, request 없이도 receive가 일어난다.
Http
- String으로 정보를 통신한다.
- keep-alive로 지속적인 연결은 가능하지만, 기본적으론 close 되어 있으며, request를 해야만 receive가 일어난다.
속도는 tcp/ip기반 소켓을 쓰는 것이 빠르다. 항상 연결되어있고 바인딩 과정에 http 변환 과정 등이 생략되기 때문이다. 연결 지향/동기식 통신이 필요하다면 tcp/ip 소켓 통신을 이용해야 한다.
Docker와 VM의 차이점
- VM은 가상화된 하드웨어에 게스트 OS가 올라가는 구조로 호스트와 완벽하게 분리된다.
- 도커 컨테이너의 경우 도커 엔진 위에 애플리케이션에 필요한 바이너리만 올라간다. 즉 호스트의 OS 자원을 공유한다. 따라서 도커가 용량상으로 유리하고 VM은 io처리 시 호스트 OS를 거쳐가야 하므로 도커에 비해 느리다.
도커의 장점
- 빠르게 변경사항을 적용하고 이미지로 만들어 쉽게 배포가 가능하다. 즉, 스케일 아웃을 엄청 쉽고 단순하게 가져갈 수 있다.
- 오케스트레이션까지 제공되어 여러대의 호스트에 여러 대의 컨테이너를 동시에 배포하면서 관리도 가능하다.
도커의 단점
- 도커는 호스트의 커널을 공유하기 때문에 커널의 보안이 뚫리면 모든 컨테이너가 뚫리기 된다. 즉 보안이 VM에 비해 완벽하지 않다.
- VM은 여러 가지 OS를 올릴 수 있는데 반해 도커 컨테이너는 호스트의 OS를 공유하기 때문에 OS 선택의 자유로움이 떨어진다.
DI란? ( Dependancy Injection 의존성주입)
- 클래스 사이의 의존관계를 가진 bean 설정 정보를 Framework가 자동으로 연결해 주는 것.
- Framework에 의해 동적으로 주입되므로 여러 객체 간의 결합도가 줄어든다.
- IoC(Inversion of Control) 제어의 역전. 프로그램의 제어권을 framework가 가져가는 것. 어떠한 일을 하도록 만들어진 framework에 제어의 권한을 넘김으로써 클라이언트 코드가 신경 써야 할 것을 줄이는 전략으로 di와 ioc는 같은 개념으로 사용된다.
- 개발자가 모든 제어의 중심이지만 코드 전체에 대한 제어는 framework가 한다. 개발자는 설정(xml, annotation 등)만 하고 나머지는 Container가 알아서 처리한다.
AOP란?
aop는 애플리케이션에서의 관심사의 분리(기능의 분리), 핵심적인 기능에서 부가적인 기능을 분리한다. 분리한 부가기능을 Aspect라는 독특한 모듈 형태로 만들어서 설계하고 개발하는 방법론이다. AOP는 부가기능을 Aspect로 정의하여, 핵심기능에서 부가기능을 분리함으로써 핵심기능을 설계하고 구현할 때 객체지향적인 가치를 지킬 수 있도록 도와주는 개념이다.
타겟(Target)
- 핵심 기능을 담고 있는 모듈로 타겟은 부가기능을 부여할 대상이 된다.
어드바이스(Advice)
- 어드바이스는 타겟에 제공할 부가기능을 담고 있는 모듈이다.
조인포인트(Join Point)
- 어드바이스가 적용될 수 있는 위치를 말한다.
- 타겟 객체가 구현한 인터페이스의 모든 메서드는 조인 포인트가 된다.
포인트 컷(Pointcut)
- 어드바이스를 적용할 타겟의 메서드를 선별하는 정규표현식이다.
- 포인트컷 표현식은 execution으로 시작하고 메서드의 Signature를 비교하는 방법을 주로 이용한다.
애스펙트(Aspect)
- 애스펙트는 AOP의 기본 모듈이다.
- 애스펙트 = 어드바이스 + 포인트컷
- 애스펙트는 싱글톤 형태의 객체로 존재한다.
어드바이저(Advisor)
- 어드바이저 = 어드바이스 + 포인트컷
- 어드바이저는 Spring AOP에서만 사용되는 특별한 용어이다.
위빙(Weaving)
- 위빙은 포인트컷에 의해서 결정된 타겟의 조인 포인트에 부가기능(어드바이스)를 삽입하는 과정을 뜻한다.
- 위빙은 AOP가 핵심기능(타겟)의 코드에 영향을 주지 않으면서 필요한 부가기능(어드바이스)를 추가할 수 있도록 해주는 핵심적인 처리과정이다.
CI ( Continuous Integration )지속적인통합이란?
지속적으로 품질관리를 적용하는 프로세스를 실행하는 것. 초기에 자주 통합해서 발생하는 문제를 조기에 발견하고, 피드백 사이클을 짧게 하여 소프트웨어 개발의 품질과 생산성을 향상하는것.
Public Cloud
- Iass(Infrastructure as a service)
- lass의 경우에는 Physical 한 Hadware는 관리를 하지 않고 담당자가 사용하고자 하는 OS만 선택을 하여, 선택한 VM에 대해서만 관리를 하면 되는 것이다.
- Pass(Platform as a service)
- Pass의 경우에는 개발자가 Service나 OS 등 많은 요건을 원하는것이 아닌 자신이 개발을 한 Source를 실행시켜줄 Infra만 있으면 되며, 다른 것에 대해서는 관리를 하지 않아도 되는 것을 말한다.
- Sass(Software as a service)
- Sass는 facebook, office 365같은 아이디나 계정만 있으면 사용이 가능한 서비스를 말한다.
Container Orchestration
컨테이너 배포 관리는 흔히 컨테이너 오케스트레이션이라고 한다. 컨테이너 오케스트레이션의 목적은 여러 컨테이너의 배포 프로세스를 최적화하는 데 있으며, 이것은 컨테이너와 호스트의 수가 증가함에 따라 점점 더 가치가 있게 된다. 이러한 유형의 자동화를 오케스트레이션이라고 한다. 오케스트레이션은 배포 기능뿐만 아니라 다음과 같은 기능을 포함할 수 있다.
- 컨테이너 자동 배치 및 복제
- 컨테이너 그룹에 대한 로드밸런싱
- 컨테이너 장애 복구
- 클러스터 외부에 서비스 노출
- 컨테이너 추가 또는 제거로 확장 및 축소
- 컨테이너 서비스 간의 인터페이스를 통한 연결 및 네트워크 노출 제어
infra automation
더 빠른 애플리케이션 제공을 위해서는 DevOps환경에서 올바른 도구를 사용해야 한다. 서버 프로비저닝, 구성관리, 자동화된빌드, 코드배포 및 모니터링과 같은 모든 요구 사항에 맞는 단일 도구는 없다. 많은 요인들이 인프라에서 특정 도구의 사용을 결정한다.
– Infrastructure as Code
Terraform, Ansible, Chef, Puppet
– Continuous Integration/Deployment
Jenkins, Vagrant, Docker
– Config/Secret Management
Consul, etcd, Vault
– Monitoring
Prometheus & Alert Manager, New Relic, Datadog
쓰레드 덤프
- 시스템이 느리거나, 행이 걸릴 경우 스레드 덤프를 확인한다.
- kill -3 pid 또는 jstack pid를 이용하여 해당 application의 standard out을 통해 출력한다.
- 스레드 덤프는 변화 추이를 보기 위해 10초 단위로 적어도 3번은 덤프를 떠야 한다.
- 스레드 덤프에는 Thread Dump, Deadlock detection, Heap summary가 포함된다.
힙덤프
- OutOfMemory 크래시, 메모리 릭이 발생할 경우 힙덤프를 확인한다.
- jmap 명령을 통해 힘 덤프롤 생성한다.
- 힙덤프는 문제 당시의 덤프를 떠야하며, 매우 큰 파일이며 힙에 있는 모든 오브젝트들에 대한 기록을 가지고 있다.
- 이 파일을 통해 힙 메모리에 대한 확인이 가능하며, 메모리 릭과 같은 현상을 파악할 수 있다.
GC 로그확인
tomcat띄울때 인자로 -verbose:gc를 주면 GC가 일어날때마다의 로그를 찍어, MinorGC의 추이와 FullGC의 메모리 변화 추이를 볼수 있다.
빅오 표기법
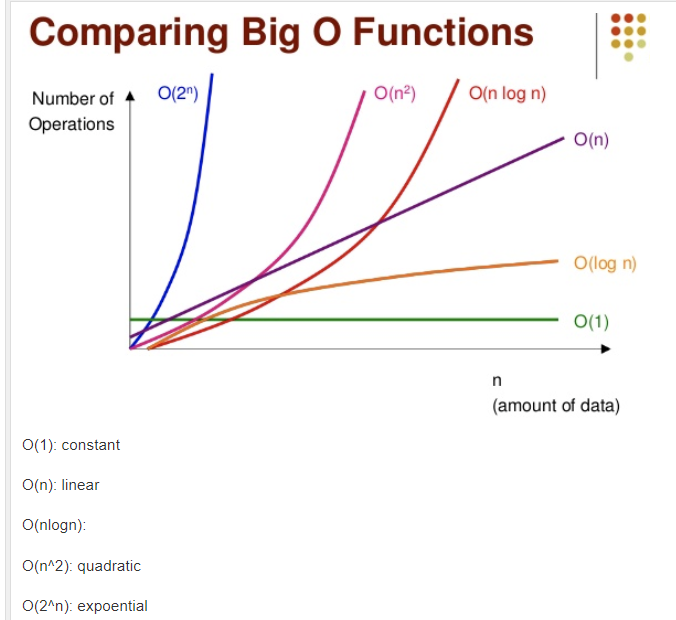
- O(1) – 상수시간 – 문제를 해결하는데 오직 한 단계만 처리함
- O(log n) – 문제를 해결하는데 필요한 단계들이 연산마다 특정요인에 의해 줄어듬
- O(n) 문제를 해결하기 위한 단계의 수와 입력값 n이 1:1 관계를 가짐
- O(nlogn) – 문제를 해결하기 위한 단계의 수가 N*(log2N)번만큼의 수행시간을 가진다.
- O(n^2) – 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱.
RestAPI란
웹에 존재하는 모든 자원(이미지, 동영상, DB)에 고유한 URI를 부여해 사용
URI는 정보의 자원을 표현해야 한다. 자원에 대한 행위는 HTTP Method(GET, POST, PUT, DELETE 등)로 표현한다.
Http Method
- GET
- 서버에게 Resource를 요청하는데 사용
- HEAD
- GET과 동일하지만 서버에서 Body를 Return 하지 않음
- Resource를 받지 않고 오직 찾기만 원할때
- object가 존재할 경우 응답의 상태 코드를 확인할때
- 서버의 응답 헤더를 봄으로써 Resource가 수정 되었는지 확인
- PUT
- 서버에 문서를 쓸때 사용 (GET과 반대)
- PUT 메소드는 서버가 Client 요청의 Body를 확인한다.
- 요청된 URL에 정의된 새로운 Resource를 생성하기 위함
- 요청된 URL의 리소스가 존재할 경우 대체함
- POST
- Server에 Input Data를 보내기 위함 (HTML form에 많이 사용)
- PUT vs. POST
- PUT은 서버의 Resource에 Data를 저장하기 위한 용도
- POST는 서버에 Data를 보내기 위한 용도
- OPTION
- Target Server의 지원 가능한 method(ex> GET, POST …)를 알아보기 위함
- DELETE
- 요청 Resource를 삭제하도록 요청
- HTTP 규격에는 Client의 요청에도 서버가 무효화 시킬수 있도록 정의되어 있어 DELETE Method는 항상 보장되지 않는다.
&와 && 차이
&는 두 조건을 무조건 검사하는것이고, &&는 첫번째 조건이 참일때만 검사하는것
폴링
브라우저가 일정한 주기로 http요청을 보내는 방식. 실시간 데이터의 업데이트 주기는 예측하기 어려우므로, 그에 따른 불필요한 서버 및 네트웍 부하가 늘어난다.
롱폴링
Http요청시 서버는 해당 요청을 일정 시간 동안 대기시킨다. 대기 시간안에 데이터가 업데이트되었다면 그 즉시 클라이언트에게 응답을 보내고 전달받은 데이터를 처리 후 서버로 재요청을 시작한다.
웹소켓
Server와 client가 지속적으로 연결을 유지하고 양방향으로 통신을 하는 방식. 일반 소켓통신과 달리 Http 프로토콜을 이용하고, 연결 이후의 통신은 웹소켓이 한다.
싱글톤이란?
어떤 클래스에 대하여 생성자가 여러 번 호출되더라도 단 하나의 인스턴스만 생성하여 재사용하는 것을 말한다. 고정된 메모리 영역을 얻으면서 한 번의 new로 인스턴스를 사용하기 때문에 메모리 낭비를 방지할 수 있다. 또한 싱글톤으로 만들어진 클래스의 인스턴스는 전역 인스턴스이기 때문에 다른 클래스의 인스턴스들이 데이터를 공유하기 쉽다.
// 일반적인 방법
public class SingletonExample {
private static SingletoneExample instance;
private SingletonExample() {}
public static synchronized SingletoneExample getInstance() {
if(instance == null)
instance = new SingletoneExample();
return instance;
}
}
// 개선1 - 존재여부를 먼저 체크하여 synchronized를 바로 타지 않도록 수정
public class SingletoneExample {
private volatile static SingletonExample instance;
private SingletoneExample() {}
public static SingletoneExample getInstance() {
if(instance == null) {
synchronized (SingletoneExample.class) {
if(instance == null)
instance = new SingletoneExample();
}
}
return instance;
}
}
/* 개선2 - 클래스안에 클래스(Holder)를 두어 JVM의 ClassLoader 매커니즘과 Class가 로드되는 시점을 이용한 방법. 개발자의 실수를 줄이고 JVM의 클래스 초기화 과정에서 보장되는 원자적 특성을 이용하여 싱글턴의 초기화 문제에 대한 책임을 JVM에게 떠넘긴다. */
public class SingletoneExample {
private SingletoneExample() {}
private static class LazyHolder {
public static final SingletoneExample INSTANCE = new SingletoneExample();
}
public static SingletoneExample getInstance() {
return LazyHolder.INSTANCE;
}
}
String, StringBuffer, StringBuilder 차이
String은 불변 객체로 내용이 바뀌면 내부적으로 새로운 인스턴스를 생성하는 과정이 추가되어 자주 변경이 이루어지는 문자열을 저장하는데는 적합하지 않다. StringBuffer와 StringBuilder는 String과 다르게 mutable(변경 가능)하다. 문자열 연산에 있어서 클래스를 한번만 만들고 연산이 필요할 때 크기를 변경시켜서 문자열을 변경한다. 따라서 문자열 연산이 자주 있을때 사용하면 좋다. StringBuffer는 멀티스레드 환경에서 동기화가 가능하다. 즉 thread-safe 하다. StringBuilder는 동기화를 지원하지 않지만, StringBuffer에 비해 속도는 빠르다.
트랜잭션
하나의 논리적 작업 단위를 구성하는 일련의 연산들의 집합을 트랜잭션이라 한다.
Atomicity(원자성)
트랜잭션의 연산은 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야 한다. 트랜잭션 내의 모든 명령은 반드시 완벽히 수행되어야 하며, 모두가 완벽히 수행되지 않고 어느 하나라도 오류가 발생하면 트랜잭션 정부가 취소되어야 한다.
Consistency(일관성)
트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다. 시스템이 가지고 있는 고정 요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다.
Isolation(독립성, 격리성)
둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없다. 수행 중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다.
Durability(영속성, 지속성)
성공적으로 완료된 트랜잭션의 결과는 시스템이 고장 나더라도 영구적으로 반영돼야 한다.
Commit 연산
Commit은 한 개의 트랜잭션에 대한 작업이 성공적으로 끝났고 데이터베이스가 일관된 상태에 있을 때, 트랜잭션이 행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산이다.
Rollback 연산
Rollback은 하나의 트랜잭션 처리가 비정상적으로 종료되어 데이터 베이스의 일관성을 깨뜨렸을때, 이 트랜잭션의 일부가 정상적으로 처리되었더라도 트랜잭션의 원자성을 구현하기 위해 트랜잭션이 행한 모든 연산을 취소하는 연산이다.
커넥션 풀이란
데이터 베이스와 연결된 커넥션을 미리 만들어서 pool속에 저장해 두고 있다가 필요할 때 커넥션을 pool에서 다시 뜨고 pool에 반환하는 기법을 말한다.
- pool속에 미리 커넥션이 생성되어 있기 때문에 커넥션을 생성하는데 드는 연결 시간이 소비되지 않는다.
- 커넥션 풀을 사용하면 커넥션을 생성하고 닫는 시간이 소모되지 않기 때문에 그만큼 애플리케이션 처리 속도가 빨라 지며, 한 번에 생성될 수 있는 커넥션 수를 제어하기 때문에 동시 접속자 수가 몰려도 웹 애플리케이션이 쉽게 다운되지 않는다.
- 커넥션의 수를 일정하게 제한하기 때문에 데이터베이스에 대한 부하를 조절할 수 있다.
3 way handshake
tcp 3 way handshake는 tcp/ip 프로토콜을 이용해서 통신을 하는 응용프로그램이 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해 상대방 컴퓨터와 사전에 세션을 수립하는 과정이다. 3 way handshake는 tcp/ip연결을 초기화 할 때 사용한다.
- A 클라이언트는 B서버에 접속을 요청하는 SYN 패킷을 보낸다. A클라이언트는 SYN을 보내고 SYN/ACK 응답을 기다리는 SYN_SENT상태가 된다.
- B서버는 SYN요청을 받고 A클라이언트에게 요청을 수락한다는 ACK와 SYN flag가 설정된 패킷을 발송하고 A가 다시 ACK로 응답하기를 기다린다. B서버는 SYN_RECEIVED상태가 된다.
- A클라이언트는 B서버에 ACK를 보내고 이후부터는 연결이 이루어지고 데이터가 오가게 된다. 이때 B서버의 상태가 ESTABLISHED이다.
4way handshake
tcp/ip의 세션을 종료하기 위해 수행되는 절차
- 클라이언트가 연결을 종료하겠다는 FIN 플래그를 전송한다.
- 서버는 일단 확인(ACK) 메시지를 보내고 자신의 통신이 끝날 때까지 기다리는데 이상태가 TIME_WAIT상태이다.
- 서버는 통신이 끝났으면 연결이 종료되었다고 FIN플래그를 전송한다.
- 클라이언트는 확인(ACK)했다는 플래그를 보낸다.
서블릿이란
서블릿이란 자바를 사용하여 웹을 만들기 위해 필요한 기술이다. 클라이언트가 어떠한 요청을 하면 그에 대한 결과를 다시 전송해 주어야 하는데, 이러한 역할을 하는 자바 프로그램이 서블릿이다. 예를 들어, 어떠한 사용자가 로그인을 하려고 할 때 사용자는 아이디와 비밀번호를 입력하고 로그인 버튼을 누른다. 그때 서버는 클라이언트의 아이디와 비밀번호를 확인하고 다음 페이지를 띄워주어야 하는데 여기서 웹서버가 동적인 페이지를 제공할 수 있도록 도와주는 애플리케이션이 서블릿이다.
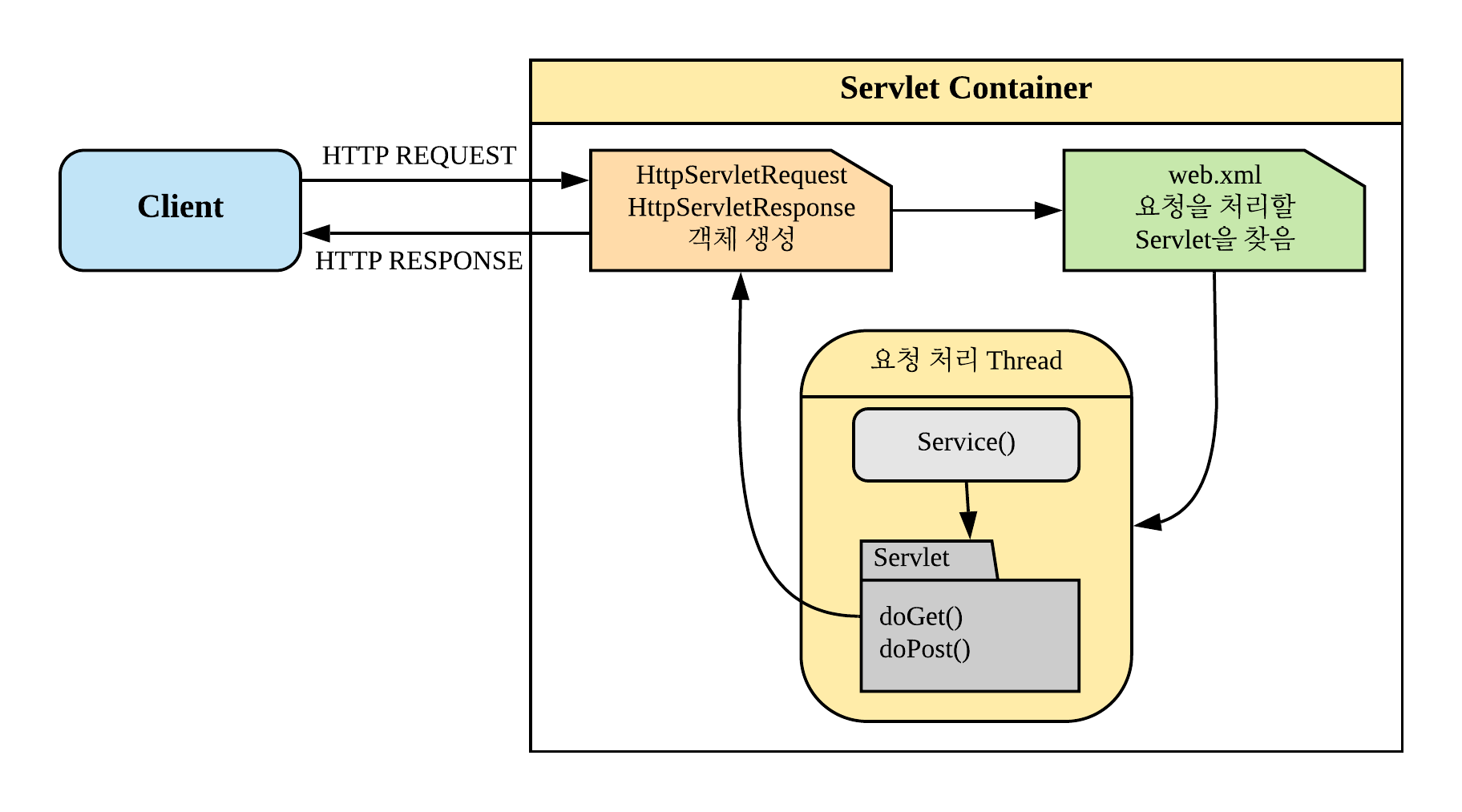
- 사용자가 URL을 클릭하면 HTTP REQUEST를 서블릿 컨테이너로 전송한다.
- HTTP REQUEST를 전송받은 서블릿 컨테이너는 HttpServletRequest, HttpServletResponse 두 객체를 생성한다.
- web.xml은 사용자가 요청한 URL을 분석하여 어느 서블릿에 요청할 것인지 찾는다.
- 해당 서블릿에서 service 메서드를 호출한 후 클라이언트의 POST, GET여부에 따라 doGet(), doPost()를 호출한다.
- doGet(), doPost() 메서드는 동적 페이지를 생성한 후 HttpServletResponse객체에 응답을 보낸다.
- 응답이 끝나면 HttpServletRequest, HttpServletResponse 두 객체를 소멸시킨다.
재귀 함수를 쓰는이유?
- 알고리즘 자체가 재귀적으로 표현하기 자연스러울 때.(가독성)
- 변수 사용을 줄여준다.
- mutable state(변경가능한상태)를 제거하여 프로그램 오류가 발생할 수 있는 가능성을 줄인다.
램에 데이터가 저장되는 방식
엔디언은 컴퓨터의 메모리와 같은 1차원 공간에 여러개의 연속된 대상을 배열하는 방법을 뜻한다.
빅엔디언
- 최상위 바이트 부터 차례로 저장된다.
- 0A0B0C0D는 0A-0B-0C-0D로 저장된다.
- 빅 엔디언은 사람이 숫자를 읽고 쓰는 방법과 같기 때문에 디버깅 과정에서 메모리 값을 보기 편하다.
- 네트워크 주소를 주고받을때는 빅엔디언을 사용한다.
- 상위부터 저장되므로 숫자를 비교할때는 빅 엔디언이 빠르다.
리틀엔디언
- 최하위 바이트 부터 차례로 저장된다.
- 0A0B0C0D는 0D-0C-0B-0A로 저장된다.
- 대부분의 x86 아키텍쳐의 컴퓨터는 리틀엔디언을 사용한다.
- 리틀 엔디언은 메모리에 저장된 값의 하위 바이트들만 사용할때 별도의 계산이 필요없다.
- 하위부터 저장되므로 수치 계산을 할때는 리틀엔디언이 빠르다.
2진수를 10진수로 변환
public class BinaryToDecimal {
public static void main(String args[]) {
System.out.println("값을 입력하시오. ");
Scanner input = new Scanner(System.in); // 문자열입력받고
String[] num = input.next().split("");//공백으로 나누기
int len = num.length;
int sum = 0;
for (int i = 0; i < num.length; i++) {
sum += Integer.parseInt(num[i]) * (int) Math.pow(2, len - (i + 1));
}
System.out.println(sum);
}
}
10진수를2진수로변환
public class DecimalToBinary {
public static void main(String[] args) {
Scanner scn = new Scanner(System.in);
System.out.println("값을 입력해주십시요.");
int input = Integer.parseInt(scn.next());
StringBuilder sb = new StringBuilder();
while (input / 2 > 0) {
int remain = input % 2;
input = input / 2;
sb.insert(0, remain);
}
sb.insert(0, input);
System.out.println(sb.toString());
}
}
DBMS 장단점
장점
데이터 중복의 최소화
각 응용 프로그램마다 자신의 파일이 개별적으로 유지 관리되기 때문에 저장되는 데이터의 입장에서 보면 많은 데이터가 같은 내용을 표현하며 중복 저장되고 있다. 하지만 데이터베이스는 데이터를 통합하여 구성함으로써 이러한 중복을 사전에 통제할 수 있다.
데이터의 일관성 유지
한가지를 나타내는 두개의 데이터가 있을때, 하나의 데이터만 변경이 되고 다른 하나는 변경되지 않는다면 데이터간의 불일치성, 모순성을 갖게 된다. 그렇다면 서로 상충되는 정보를 제공하게 되고 데이터베이스의 유용성을 저해하게 된다. 데이터베이스 관리 시스템은 바로 이 데이터의 중복을 제어하고 중앙집중식 통제를 통해 데이터의 일관성을 유지할 수 있다.
데이터의 무결성 유지
데이터 중복성이 완전히 제거된다고 해도 허용되지 않는 값이나 부정확한 데이터가 여러가지 경로에 의해 데이터베이스에 잠입될 수 있다. 데이타베이스 관리 시스템은 데이터가 생성 조작될 때마다 제어 기능을 통해 그 유효성을 검사함으로서 데이터의 무결성을 유지할 수 있다.
데이터의 공용성
기존 여러 응용프로그램들이 수행하던 데이터에 대한 유지관리 부담을 면제시켜줄 뿐만 아니라 새로 개발하는 응용 프로그램에 대해서도 데이터 구성에 신경 쓸 필요없이 응용 자체에만 전념할 수 있게 해준다.
데이터의 보안보장
데이타베이스 관리 시스템은 데이타베이스를 중앙 집중식으로 총괄함으로서 데이타베이스의 고나리 및 접근을 효율적으로 통제할 수 있다. 정당한 사용자, 허용된 데이터를 확인함으로서 모든 데이터에 대해 철저한 보안을 제공한다.
단점
- 운영비의 증대
데이타베이스는 고가의 제품이고 컴퓨터 시스템의 자원을 많이 사용한다. 특히, 주기억장치를 많이 차지하기 때문에 데이타베이스를 운영하기 위해서는 메모리 용량이 더 필요하게 되고, 더 빠른 CPU를 요구하게 된다.
- 자료 처리의 복잡화
데이타베이스는 상이한 여러 타입의 데이타가 서로 관련되어있다. 응용 프로그램은 이러한 상황 속에서 여러 제한점을 가지고 수행될지도 모른다. 따라서 응용 시스템은 설계시간이 길어지게 되고 보다 전문적, 기술적 기술이 필요하기 때문에 고급 프로그래머가 필요하다.
- 시스템의 취약성
데이타베이스는 통합된 시스템이기 때문에 그 일부의 고장이 전체 시스템을 정지시켜 시스템 신뢰성과 가용성을 저해할 수 있다.
- 복잡한 예비와 회복
데이타베이스는 구조가 복잡하고 여러 사용자가 동시에 공용하기 때문에 예비 조치나 사후 회복기법을 수립해 놓는것이 어렵다.
RDBMS vs NoSql
RDB 장점
명확하게 정의된 스키마, 데이터 무결성 보장. 관계는 각 데이터를 중복없이 한번만 저장한다.
NoSql 장점
- 스키마가 없어, 훨씬 더 유연하다, 언제든지 저장된 데이터를 조정하고, 새로운 필드를 추가할 수 있다.
- 데이터는 어플리케이션이 필요로 하는 형식으로 저장되고, 이렇게 함으로서 데이터 읽어오는 속도가 빨라진다.
- 수직 및 수평 확장이 가능하므로 데이타베이스가 애플리케이션에서 발생시키는 모든 읽기/쓰기요청을 처리할 수 있다.
RDB 단점
- 상대적으로 덜 유연하다. 데이터 스키마는 사전에 계획되고 알려져야 한다.
- 관계를 맺고 있기 때문에 join문이 많은 매우 복잡한 쿼리가 만들어 질수있다.
- 수평적 확장이 어렵고 대체로 수직적 확장만 가능하다.
NoSql 단점
- 유연성 때문에 데이터 구조 결정을 하지 못하고 미루게 될수 있다.
- 데이터가 여러 컬렉션에 중복되어 있기 때문에, 수정을 해야하는경우 모든 컬렉션에서 수행되야한다.
RDB는 언제 사용하는게 좋은가
- 관계를 맺고 있는 데이타가 자주 변경되는 애플리케이션일 경우
- 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSql은 언제 사용하는 것이 좋은가
- 정확한 데이터 구조를 알수 없거나 구조가 변경/확장 될수 있는경우
- 읽기 처리를 자주하지만, 데이터를 자주 변경하지 않는 경우(한번의 변경으로 수십개의 문서를 업데이트 할 필요가 없는경우)
- 데이타베이스를 수평으로 확장해야 하는 경우(막대한 양의 데이타를 다뤄야 하는경우)
GraphQL
- Query Language는 정보를 얻기 위해 보내는 질의문(Query)를 만들기 위해 사용되는 컴퓨터 언어의 일종이다.
- GraphQL은 Server API를 통해 정보를 주고받기 위해 사용하는 Query Language이다.
- Restful api로는 다양한 기종에서 필요한 정보들을 일일히 구현하는 것이 힘들다. 즉 OS마다 필요한 정보들이 조금씩 다른데, 그 다른 부분마다 api를 구현하는 것이 힘들다.
- 정보를 사용하는 측에서 원하는 대로 정보를 가져갈수 있고, 보다 편하게 정보를 수정할 수 있도록 하는 표준화된 Query Language가 GraphQL이다.
- GraphQL API는 주로 하나의 엔드포인트를 사용한다.
- GraphQL API는 요청할때 사용한 Query문에 따라 응답의 구조가 달라진다.
장점
- HTTP 요청 횟수를 줄일수 있다.
- RestAPI처럼 리소스 종류별로 요청하는게 아니라 원하는 정보를 하나의 Query로 요청하는것이 가능하다.
- HTTP 응답 사이즈를 줄일 수 있다.
- RestAPI는 응답의 형태가 정해져있고, 필요한 부분의 정보만 부분적으로 요청하는것이 힘들다. 반면 GraphQL은 원하는 대로 정보를 요청하는 것이 가능하다.
단점
- 파일 전송등 텍스트만으로 처리하기 힘든 내용을 처리하는것이 복잡하다.
- 고정된 요청과 응답만 필요할 경우에는 Query로 인해 요청의 크기가 RestAPI보다 커진다.
뮤텍스와 세마포어 차이
공유된 자원에 여러개의 프로세스가 동시에 접근하면 문제가 발생하는데, 공유된 자원속 하나의 데이터는 한번에 하나의 프로세스만 접근할 수 있도록 제한해야 하는데 이것을 상호배제라 한다.
뮤텍스
- 한 스레드, 프로세스에 의해 소유될수 있는 Key를 기반으로한 상호배제 기법
- 뮤텍스는 상태가 0,1 두개뿐인 바이너리 세마포어이다.
- 동기화 대상이 하나뿐일때 사용하며 locking, unlocking을 사용하여 자원 사용을 조율하며 두개의 쓰레드가 동시에 자원을 사용할 수 없다.
세마포어
- 현재 공유자원에 접근할 수 있는 스레드, 프로세스의 수를 나타내는 값을 두어 상호 배제를 달성하는 기법
- 동기화 대상이 하나 이상일때 사용하며 세마포어의 값에 따라, 즉시 자원을 사용할 수 있거나, 또는 이미 다른 프로세스에 의해 자원이 사용중이면 대기해야 한다.
- 세마포어는 공통으로 관리하는 하나의 값을 이용해 상호배제를 달성한다.
DB의 실행계획이란
SQL에서 요구한 사항을 처리하기 위한 절차와 방법을 말하며 동일한 SQL에 대하여 가장 효율적인 처리방법을 찾아내는것을 의미한다. 조인순서, 조인기법(hash, merge sort 조인등등), 엑세스기법(Index Scan, Full Scan), 최적화정보(비용, 결과집합 건수, 메모리양)등의 종합적인 연산 정보로 최선의 실행계획을 수립한다.
SQL Injection
웹 어플리케이션의 뒷단에 있는 데이타베이스를 질의하는 과정 사이에 악의적인 의도를 갖는 구문을 삽입하여 원하는 대로 SQL 쿼리문을 실행하는 기법
- 입력시 특수문자여부를 검사하여 방어한다.
- SQL 서버에 오류가 발생했을시 에러메시지를 표시하지 않는다.
- PrepareStatement를 사용하여 특수문자를 자동으로 escape한다.
CSRF(Cross Site Request Forgery)
인터넷 사용자가 자신의 의도와 무관하게 공격자가 의도한 행위(수정,삭제,등록)를 웹사이트에 요청하게 하는 공격이다.
- 백엔드에서 Referer를 검증하여 승인된 도메인으로 요청시에만 처리하도록 한다.
- 사용자의 세션에 임의의 난수(token)값을 저장하고 사용자가 요청시마다 token을 같이 전달하여 검증된 토큰인 경우에만 요청을 수행하도록 한다.
XSS(Cross Site Scription)
악의적인 사용자가 공격하려는 사이트에 스크립트를 넣어 의도치 않은 행동을 실행하거나 쿠키나 세션같은 민감한 정보를 탈취하는 공격
- 웹사이트에 외부입력을 받는 input등의 form태그에 입력된 값을 검증하여 스크립트가 실행되지 않도록 필터링을 적용한다.
@Transactional 속성
isolation (격리수준)
동시에 여러 트랜잭션이 진행될 때 트랜잭션의 작업 결과를 다른 트랙잭션에서 어떻게 노출시킬지 결정하는 옵션
- Default – 사용하는 DB의 격리수준이나 DB드라이버의 기본 설정을 따른다.
- READ_UNCOMMITED – 가장낮은 격리수준으로, 트랜잭션이 커밋되기전 변화가 다른 트랜잭션에 노출된다. 성능을 극대화 할때 사용
- READ_COMMITED – 가장많이 사용되는 격리수준. 다른 트랜잭션이 COMMIT되지 않은 정보는 읽을 수 없다. 다만 하나의 트랜잭션이 읽은 로우를 다른 트랜잭션이 수정할 수 있다.
- REPEATABLE_READ – 하나의 트랜잭션이 읽은 로우를 다른 트랙잭션이 수정하는 것을 막아준다. 하지만 새로운 로우를 추가하는 것은 제한하지 않는다.
- SERIALIZABLE – 가장 강력한 격리수준으로 트랜잭션을 순차적으로 진행하기 때문에 여러 트랜잭션이 동시에 같은 데이터에 엑세스하지 못한다.
propagation (전파옵션)
트랜잭션을 시작하거나 기존 트랜잭션에 참여하는 방법을 결정하는 속성
- REQUIRED – 디폴트 속성. 미리 시작된 트랜잭션이 있으면 참여하고 없으면 새로 시작한다.
- SUPPORTS – 이미 시작된 트랜잭션이 있으면 참여하고 그렇지 않으면 트랜잭션없이 진행한다.
- MANDATORY – 이미 시작된 트랜잭션이 있으면 참여하고, 없으면 예외를 발생시킨다.
- REQUIRES_NEW – 항상 새로운 트랜잭션을 시작한다. 이미 진행중인 트랜잭션이 있으면 트랜잭션을 잠시 보류시킨다.
- NOT_SUPPORTED – 트랜잭션을 사용하지 않게 한다. 이미 진행중인 트랜잭션은 보류시킨다.
- NEVER – 트랜잭션을 사용하지 않도록 강제한다. 이미 진행중이 트랜잭션은 예외를 발생시킨다.
- NESTED – 이미 진행중인 트랜잭션이 있으면 중첩 트랜잭션을 시작한다. 중첩 트랜잭션은 부모의 커밋과 롤백에는 영향받지만 부모 트랜잭션에는 영향을 주지 않는다.
디비 인덱스 사용시 장단점
장점
- 인덱스는 select문의 where, join에서 좋은 성능을 발휘한다.
- 시스템 부하를 줄여 전체 시스템의 성능을 향상시킨다.
- 검색이 많고 수정이나 삭제가 적게 일어나는 테이블에 인덱스를 사용하면 효과적이다.
단점
- 인덱스는 데이타베이스 공간을 차지한다.
- 인덱스 생성시 많은 시간이 소요될 수 있다.
- 데이터 변경 작업시 성능이 나빠질수 있다.
- insert문의 경우 데이터 입력후 인덱스 테이블에도 생성을 해줘야 한다.
- delete문의 경우 데이터를 삭제하고 인덱스 테이블은 사용안함 표시만 하고 지우지 않으므로 불필요한 공간을 차지 할수 있다.
- update문의 경우 delete, insert가 실행되므로 해당 경우에 발생하는 인덱스의 단점을 모두 갖는다.
라이브러리와 프레임워크
라이브러리와 프레임워크의 차이는 제어 흐름에 대한 주도권이 누구에게 있느냐에 있다. 프레임워크는 전체적인 흐름을 스스로가 쥐고 있으며 사용자는 그안에서 필요한 코드를 짜 넣으며, 반면 라이브러리는 사용자가 전체적인 흐름을 만들며 라이브러리를 가져다 쓰는것이라고 볼수 있다. 프레임워크는 가져다가 사용한다기보다는 거기에 들어가서 사용한다는 느낌, 관점으로 접근할 수 있다.
어노테이션의 장단점
XML방식과 어노테이션 방식의 가장 큰 차이는, 전자는 프로젝트 전체의 컴포넌트와 의존관계를 한눈에 볼수 있다는 장점이 있고, 후자는 보다 간편한 설정이 가능하다는 장점이 있다. 시스템 복잡성이 아니라면 어노테이션은 적합하게 쓰이면 코드가 간결해지고 유지보수가 용이해진다. 어노테이션 방식은 동적으로 컨테이너 설정을 변경할때 유용하고, XML방식은 대형시스템같은 계층구조가 복잡한 곳에서 유리하다. 어노테이션은 메타 정보가 소스코드에 들어가므로 수정될때 재컴파일이 필요하고, 소스코드가 같이 제공되지 않으면 사용에 제약이 따른다.
Chaos Engineering
규모있는 시스템을 빠르게 나눠서 개발하고, 관리를 편하게 하기 위해 마이크로 서비스 아키텍쳐 같은 분산 시스템 아키텍쳐가 등장했다. 서비스별 로직을 개별서버로 분리해냈어도 각 시스템들은 여전히 서로 상호작용하고 있으며, 한군데서 장애가 발생하면 장애가 여기저기 퍼지게 된다. 더구나 이러한 문제들이 여러시스템에 걸쳐 얽히고 설켜서, 디버깅하기 어려운 상황이 발생하기도 한다. 이러한 시스템 약점을 실험을 통해 쉽게 찾을 수 있게 도와주는 방법론이 카오스엔지니어링이다.
- 시스템이 정상상태임을 측정할 수 있는 지표를 만들어야한다.
- 실험 그룹 / 대조 그룹에서 정상상태가 계속 지속될 것이라고 가정을 해둔다.
- 프로덕션 환경에서는 시스템에 영향을 미칠 수 있는 변수들을 리스트업해둔다.
- 위의 변수들을 실험 그룹에 적용하면서, 각 변수들이 시스템의 상태에 어떤 영향을 끼치는지 파악하면 된다.
")

 사용해보기")


