
AWS에서 제공하는 Athena 서비스에 대해 간단히 알아보겠습니다. Athena는 파일에 저장된 텍스트 데이터를 SQL문으로 질의할 수 있도록 기능을 제공하는 AWS 서비스입니다.
“텍스트 파일의 내용을 조회할 때 DB Table 조회하듯이 SQL문을 사용해 검색을 하면 편리하지 않을까?”
현실에서는 보통 이러한 작업을 할 때 awk, sed등의 linux command를 이용하여 파일 내의 문자열을 파싱하거나 복잡한 경우 shell script, regular expression등을 조합하여 해당 작업을 수행하였을 것입니다.
그런데 이런식으로 구성된 대량의 파일을 여러가지 조건으로 분석해야 할 경우는 어떻게 해야 할까요?
대용량 DBMS를 구축하고 대용량의 파일을 읽어 저장하는 프로그램을 만들어야 할까요?
AWS에서 제공하는 Athena를 이용하면 이러한 요구조건을 쉽게 충족할 수 있습니다. Athena는 여러 가지 제약이 있지만 고정된 규칙의 형태로 저장된(예를 들면 csv같은) 대량의 파일에 대해서 분석이 필요할 경우 유용하게 사용할 수 있는 서비스입니다.
Athena 사용시 장점
- 파일에 저장된 데이터를 분석하기 위해 DBMS를 추가적으로 구축할 필요가 없습니다. 데이터가 저장되는 스토리지 비용+쿼리당 비용만 지불하면 되므로 RDBMS에 비해 훨씬 많은 비용을 절감할 수 있습니다.
- DBMS가 필요하지 않으므로 대용량 데이터를 다룰 인력과 인프라 관리에 필요한 시간 및 인적 자원을 아낄 수 있습니다.
- Athena는 기본적으로 s3에 업로드된 파일을 읽어 분석할 수 있으므로, 거의 무제한에 가까운 데이터에 대한 분석이 가능합니다.
- 데이터 파티셔닝을 제공하기 때문에 대용량 데이터에서 요청한 데이터를 빠른 시간안에 조회할 수 있습니다.
- athena를 사용하면 생성한 데이터베이스/테이블간에 Join을 통한 결과 조회가 가능합니다.
Athena 사용시 단점
- 질의 속도가 DBMS 보다는 느리므로 실시간 데이터를 다루는 Frontend에는 사용하기 어렵고 Backend에서 대용량 데이터 추출 및 분석하는 용도로 적합합니다.
- 대용량의 파일을 질의하는데 목적이 있으므로 SELECT, INSERT 기능만 사용가능하며 UPDATE, DELETE 기능은 제공하지 않습니다. 따라서 지속적으로 자주 변경되거나 삭제되는 데이터를 다루는데는 Athena가 적합하지 않습니다.
Athena 사용예시 – Accesslog 분석
alb log 활성화
aws elb를 사용중이라면 accesslog를 s3로 바로 보낼 수 있습니다.
EC2 – Loadbalancers : 활성화할 elb선택 후 Description 탭에서 Configure access logs를 선택하여 s3로 로그를 쌓도록 설정합니다.
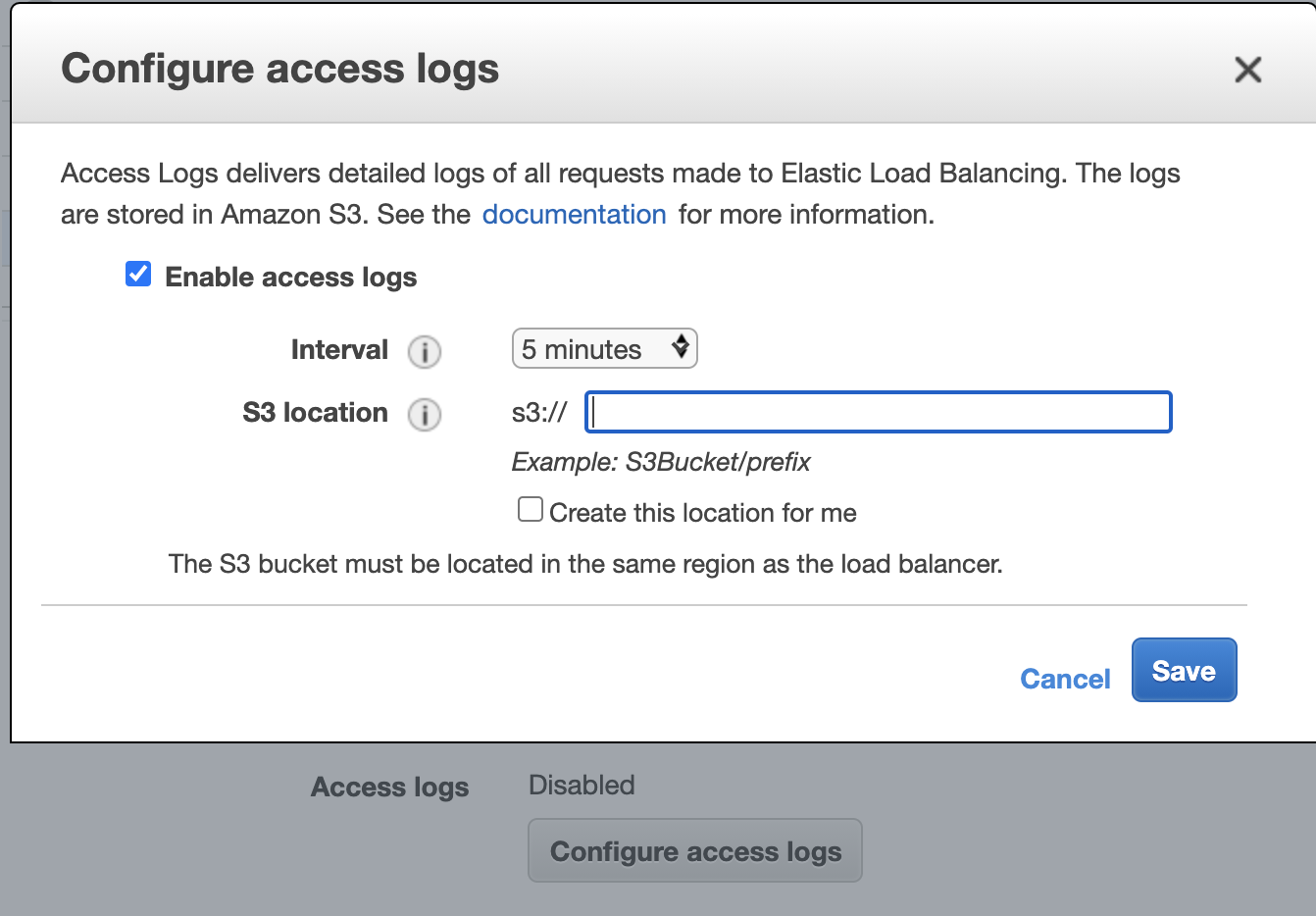
위와 같이 생성을 하면 Interval 기간이 지난후에 s3의 아래위치에 데이터가 쌓인것을 확인할 수 있습니다.
s3://[bucketName]/AWSLogs/[AccountId]/elasticloadbalancing/[year]/[month]/[day]/[로그파일].log
athena database/table 생성
athena를 처음 사용하는 것이면 query result가 저장되는 s3 location을 지정해 줍니다.
s3 – Settings
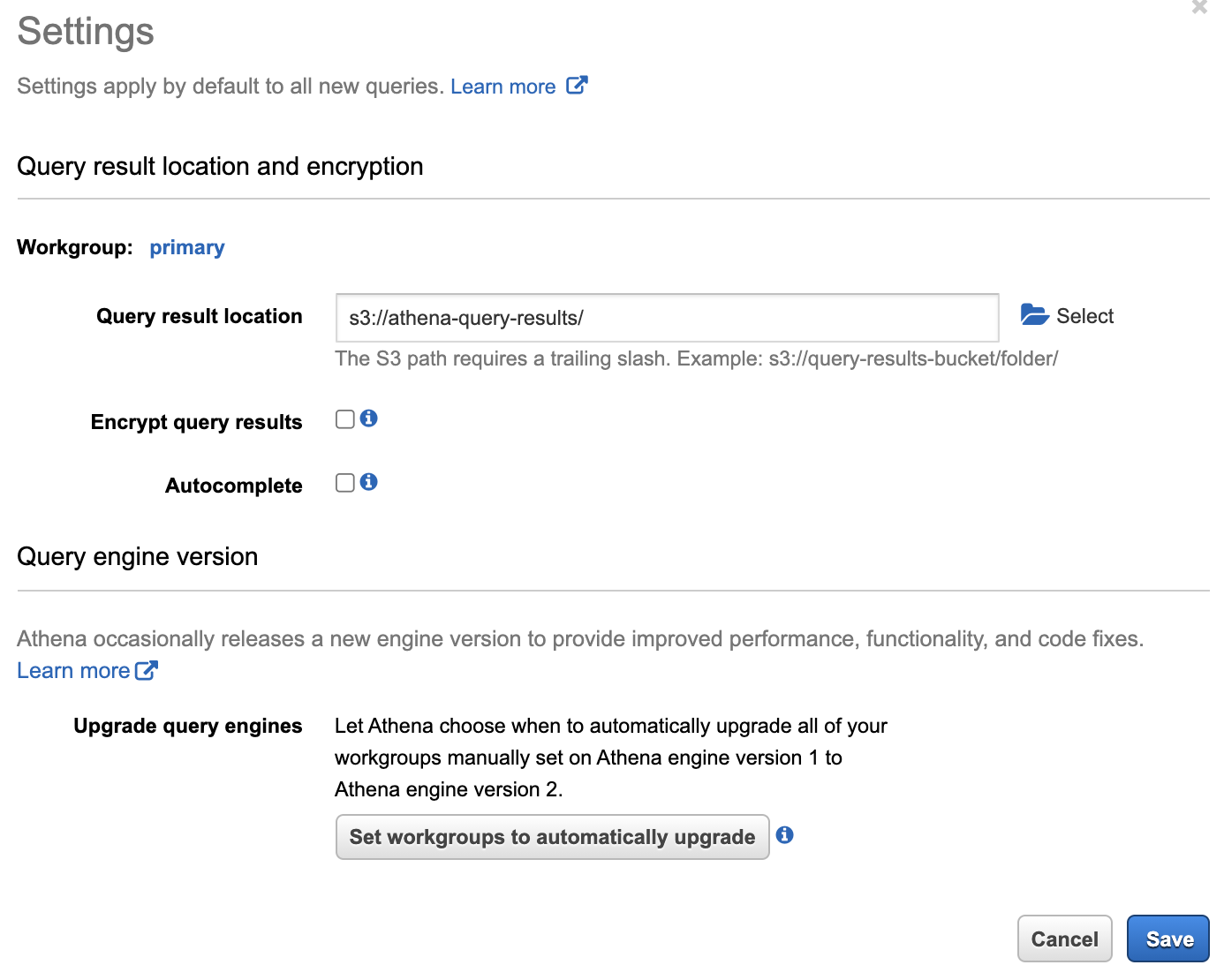
Database 생성
기존에 생성되어 있는 default db를 사용해도 됩니다. 하지만 데이터의 구분을 위해 database를 아래 명령으로 생성합니다.
create database alb_db
Table 생성
CLB(Classic Load Balancer), ALB(Application Load Balancer)의 AccessLog 테이블 스키마가 다르므로 확인 후 테이블을 생성합니다.
CLB
https://docs.aws.amazon.com/ko_kr/athena/latest/ug/elasticloadbalancer-classic-logs.html
CREATE EXTERNAL TABLE IF NOT EXISTS alb_db.elb_logs ( timestamp string, elb_name string, request_ip string, request_port int, backend_ip string, backend_port int, request_processing_time double, backend_processing_time double, client_response_time double, elb_response_code string, backend_response_code string, received_bytes bigint, sent_bytes bigint, request_verb string, url string, protocol string, user_agent string, ssl_cipher string, ssl_protocol string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1', 'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \\\"([^ ]*) ([^ ]*) (- |[^ ]*)\\\" (\"[^\"]*\") ([A-Z0-9-]+) ([A-Za-z0-9.-]*)$' ) LOCATION 's3://your_log_bucket/prefix/AWSLogs/AWS_account_ID/elasticloadbalancing/';
ALB
https://docs.aws.amazon.com/athena/latest/ug/application-load-balancer-logs.html
CREATE EXTERNAL TABLE IF NOT EXISTS alb_db.alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"')
LOCATION 's3://your-alb-logs-directory/AWSLogs/<ACCOUNT-ID>/elasticloadbalancing/<REGION>/';
조회(clb)
해당 월에 쌓인 로그 개수 확인
SELECT count(*) FROM "alb_db"."alb_logs" where year='2021' and month='07';
해당 월에 가장 많이 호출된 api 확인
SELECT request_verb, url_extract_path(url), count(*) FROM "alb_db"."alb_logs" where year='2021' and month='07' group by request_verb, url_extract_path(url) order by count(*) desc limit 10;
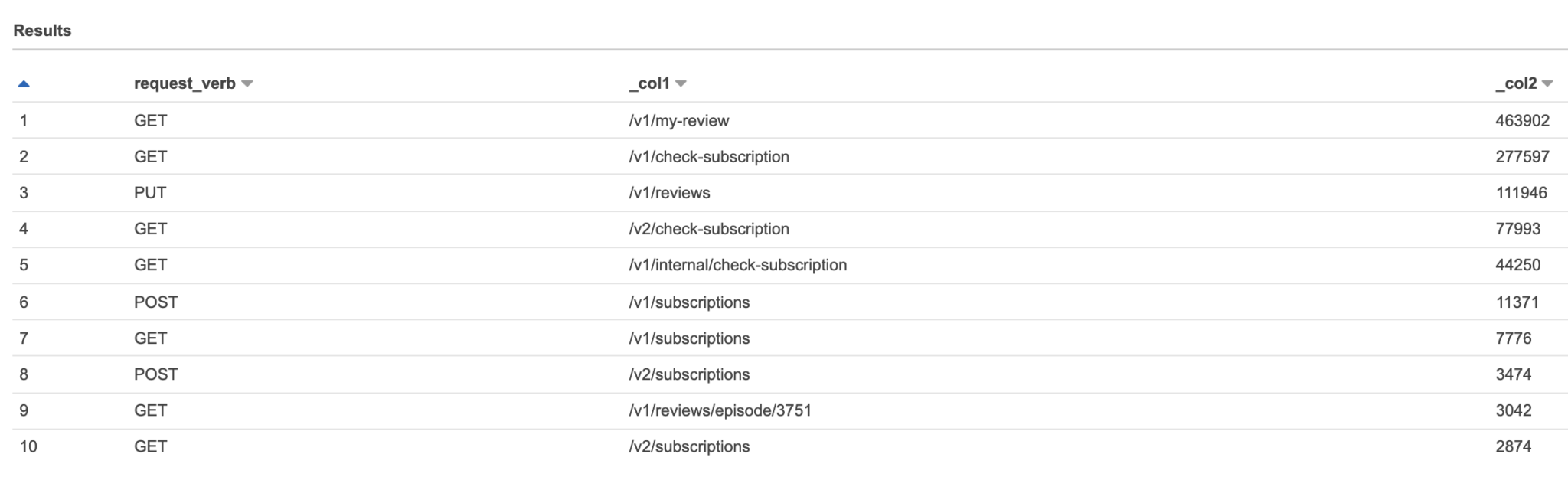
해당월에 응답 실패한 api 확인
SELECT request_verb, url_extract_path(url), elb_response_code, count(*) FROM "alb_db"."alb_logs" where year='2021' and month='07' and elb_response_code != '200' group by request_verb, url_extract_path(url), elb_response_code having count(*) > 1 order by count(*) desc limit 5;

 사용해보기")
")

 사용해보기")


")